
Azure Cosmos DB Partitioning Fundamentals
Learn the fundamentals of partitioning in Azure Cosmos DB (NoSQL API)

Today’s post is a quick introduction to partitioning with Azure Cosmos DB.
Azure Cosmos DB is a fully managed Platform as a Service (PaaS) and serves as Microsoft’s flagship distributed database solution.
How you design the partitioning strategy for your Cosmos DB is undoubtedly one of the most critical architectural decisions you’ll make when building a solution on Microsoft Azure’s highly scalable, globally distributed NoSQL database.
Request Units (RUs)
Each operation you perform in Cosmos DB — whether it’s a read, write, update, or query — consumes a certain number of Request Units (RUs).
RUs represent a normalized measure of system resources such as CPU, memory, and IOPS (input/output operations per second) required to perform a given operation. This abstraction makes performance predictable — instead of worrying about the underlying infrastructure, you only manage RUs.
The amount of RUs consumed depends on several factors:
Item size – larger JSON documents consume more RUs.
Operation type – writes and queries typically cost more than point reads.
Query complexity – filters, cross-partition queries, and sorting increase RU consumption.
Indexing – since Cosmos DB automatically indexes all properties by default, write operations cost more if you have large or deeply nested documents.
You provision throughput in RUs per second (e.g., 400 RU/s), which defines how much performance capacity your container or database can handle. If your workload exceeds that capacity, Cosmos DB starts to throttle requests, returning a 429 (Request Rate Too Large) response until throughput is available again.
You can monitor RU consumption using the Azure Portal, SDK, or query metrics to identify and optimize expensive operations.
Basic Database Structure
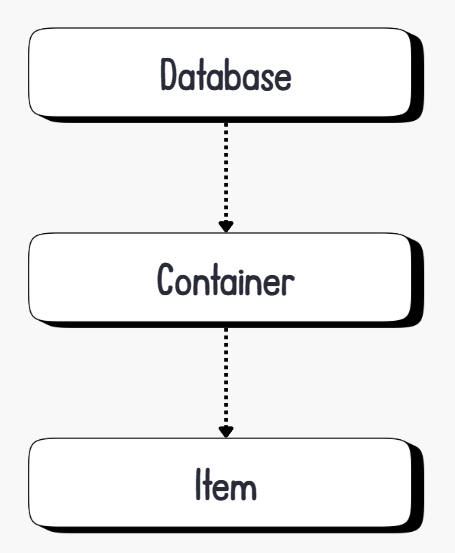
In the Azure Cosmos DB NoSQL API, the data model consists of three main components — database, container(s), and item(s) — as illustrated in the diagram below.
A database is the top-level logical namespace that groups one or more containers.
A container is the fundamental unit of scalability and throughput. It holds a collection of JSON documents (items) and defines the partition key used to distribute data across partitions.
An item is a single JSON document stored within a container. Each item must include an
idproperty and a value for the partition key.
What is Partitioning?
Partitioning literally means dividing into parts. In Azure Cosmos DB, partitioning is a core mechanism that enables your application to scale efficiently and maintain consistent performance at any size.
Whenever you create a container, you must define a partition key — a property within your JSON documents that determines how data is distributed across partitions. The partition key choice directly affects scalability, query performance, and cost efficiency.
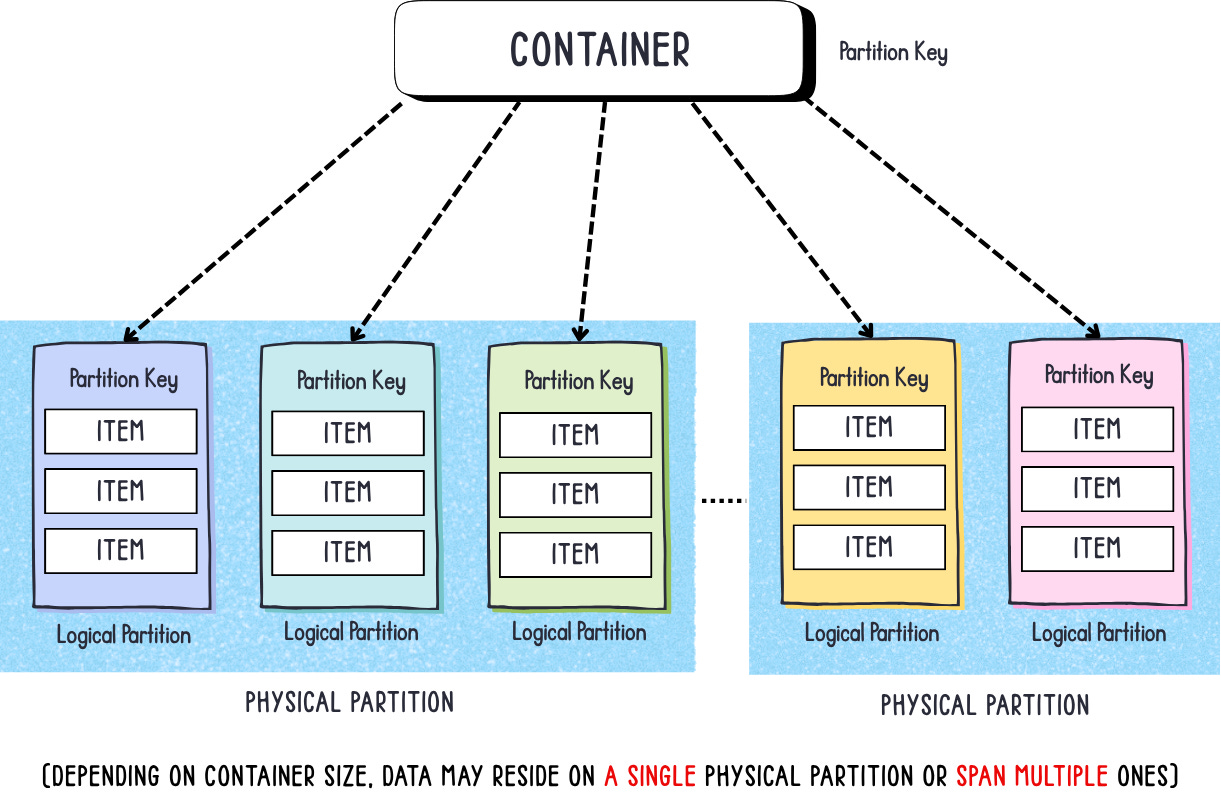
Each partition key value creates a virtual bucket called a logical partition, which contains all items that share the same partition key value. Choosing the right partition key is critical to achieving balanced data distribution. Ideally, the partition key should contain a value that never changes and one that has high cardinality — meaning it should have many unique values to evenly distribute data and requests across multiple logical partitions.
Otherwise, you may end up with what’s known as a hot partition — a single logical partition that stores a disproportionately large share of your data or handles most of the requests. This can lead to uneven throughput consumption, throttling, and degraded performance as that single partition becomes a bottleneck for your workload.
A logical partition resides within a physical partition. Depending on your data volume and throughput, a container can span multiple physical partitions. Each physical partition hosts one or more logical partitions, and Azure Cosmos DB automatically manages this distribution behind the scenes to maintain performance and scalability.
Now, let’s dive a bit deeper into partitioning strategy and discuss how to choose an effective partition key.
Partitioning Strategy
Let’s imagine we’re building a simple e-commerce website, similar to Amazon, where we have products, categories, and reviews. When users visit the site, they see a list of categories, select one, and then browse the products that belong to it.
For the sake of simplicity, we won’t attempt to replicate Amazon’s full complexity here — instead, we’ll focus on a simplified example that helps illustrate the fundamentals of partitioning in Azure Cosmos DB.
So, based on the structure we just defined, we’ll have three containers — one for products, one for categories, and one for reviews.
Now comes the interesting (and often challenging) part: choosing the right partition key for each container. The partition key determines how data is distributed and accessed, so picking the right one is essential for achieving scalability, balanced throughput, and optimal query performance.
Application accessing patterns
Whenever you choose a partition key, your starting point should always be how your application accesses the data. The way users query and interact with your data model should guide your partitioning strategy.
For our fictitious e-commerce app, when a user visits the website, they first see a list of categories and select one. After choosing a category, they’re shown a list of products that belong to it. From there, they can click on a specific product to view its details, add it to the cart, or purchase it.
Now, based on this, let’s choose the right partition key for each container, starting with the simplest one - categories.
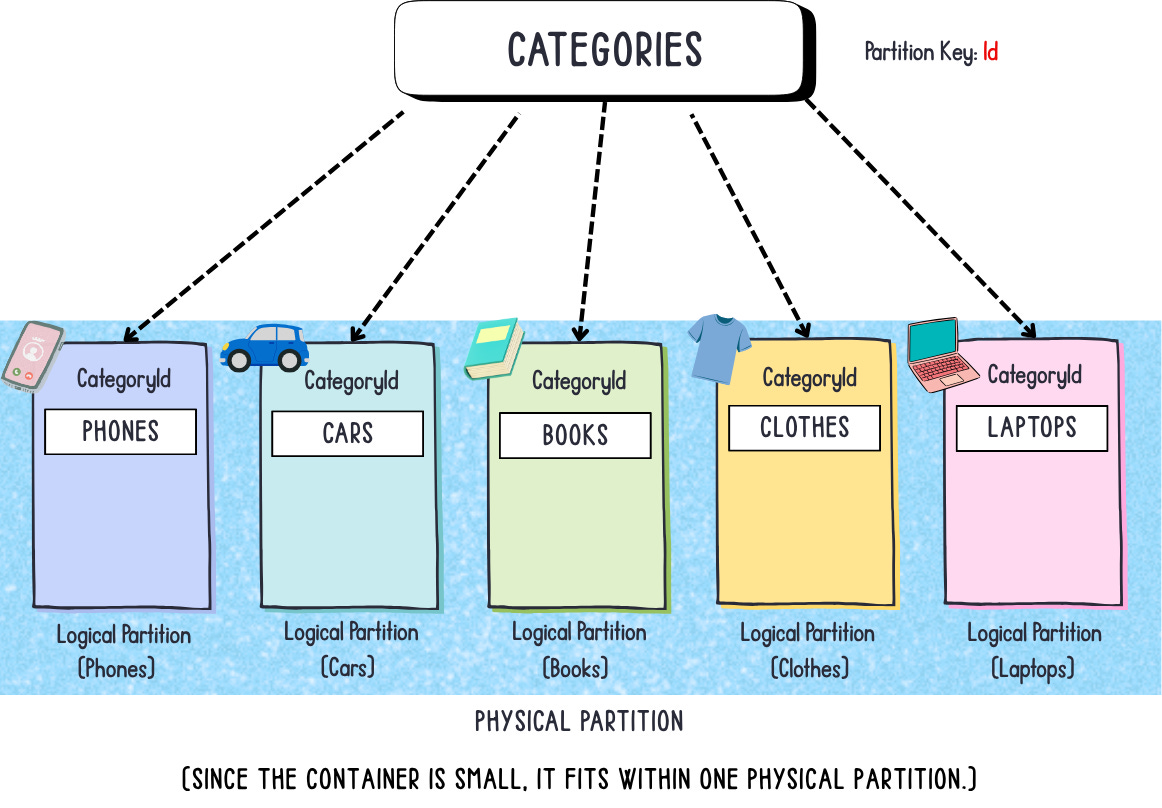
categories
This one is easy. Since we don’t have that many categories (tens and not thousands) we’ll use the id as a partition key for it. What this means is that for each category we’ll have a single logical partition.
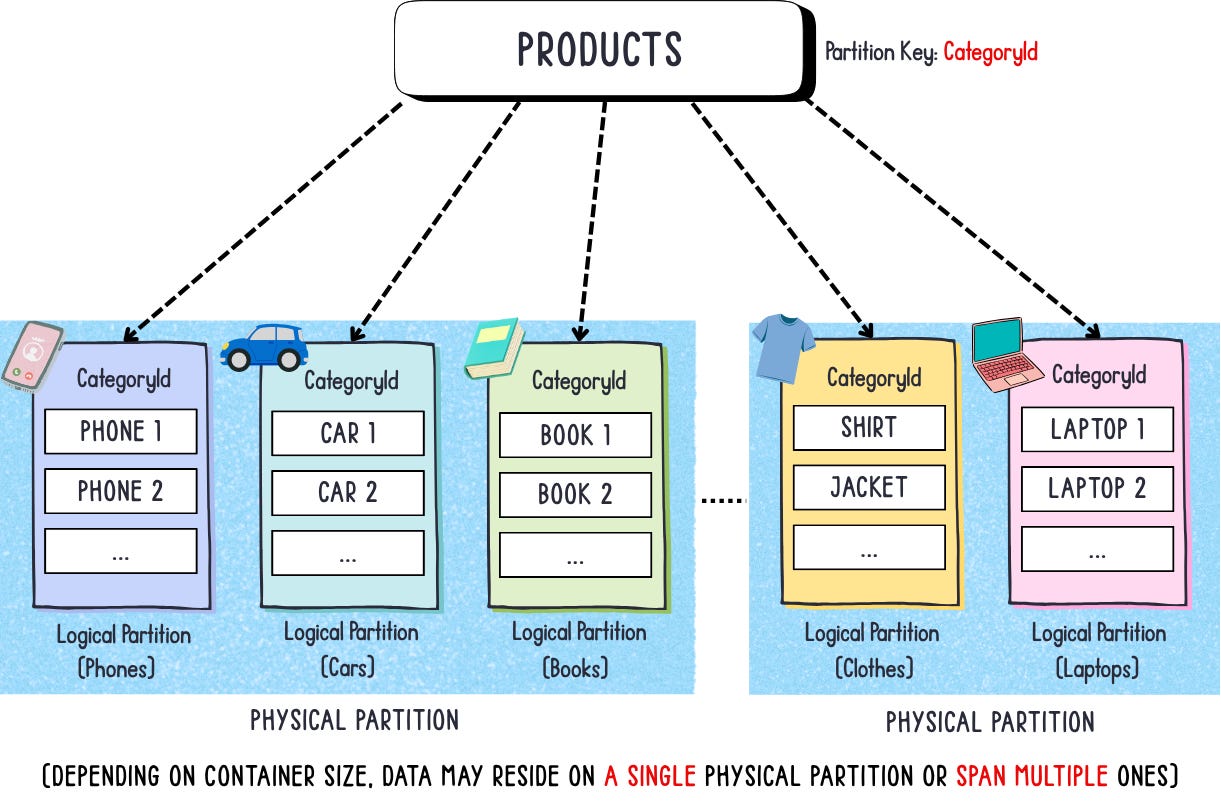
products
You might be tempted to use the product’s ID as the partition key here as well — it offers high cardinality and would evenly distribute data across partitions. While that’s not necessarily wrong, remember that our partitioning strategy is driven by how the application accesses data, not just by distribution.
In our e-commerce example, users typically browse products by category, not by individual product ID. That’s why a better choice for the Products container is CategoryID as the partition key — it aligns with the most common access pattern (fetching all products within a category) while still providing good distribution and query performance.
This approach keeps queries efficient, since the data you need (all products in a given category) is co-located within the same logical partition. As a result, Cosmos DB doesn’t have to perform a cross-partition query, which improves latency, throughput efficiency (RUs), and overall performance.
reviews
This one should be straightforward. In any e-commerce platform, reviews naturally belong to the product they describe — users leave feedback directly under the product page for others to see.
To maintain high cardinality and maximize query efficiency, we’ll use the ProductID as the partition key for the Reviews container. This way, all reviews for a given product are stored within the same logical partition, allowing the application to retrieve them with a single, efficient query — no cross-partition scans, no unnecessary RU consumption, and minimal latency.
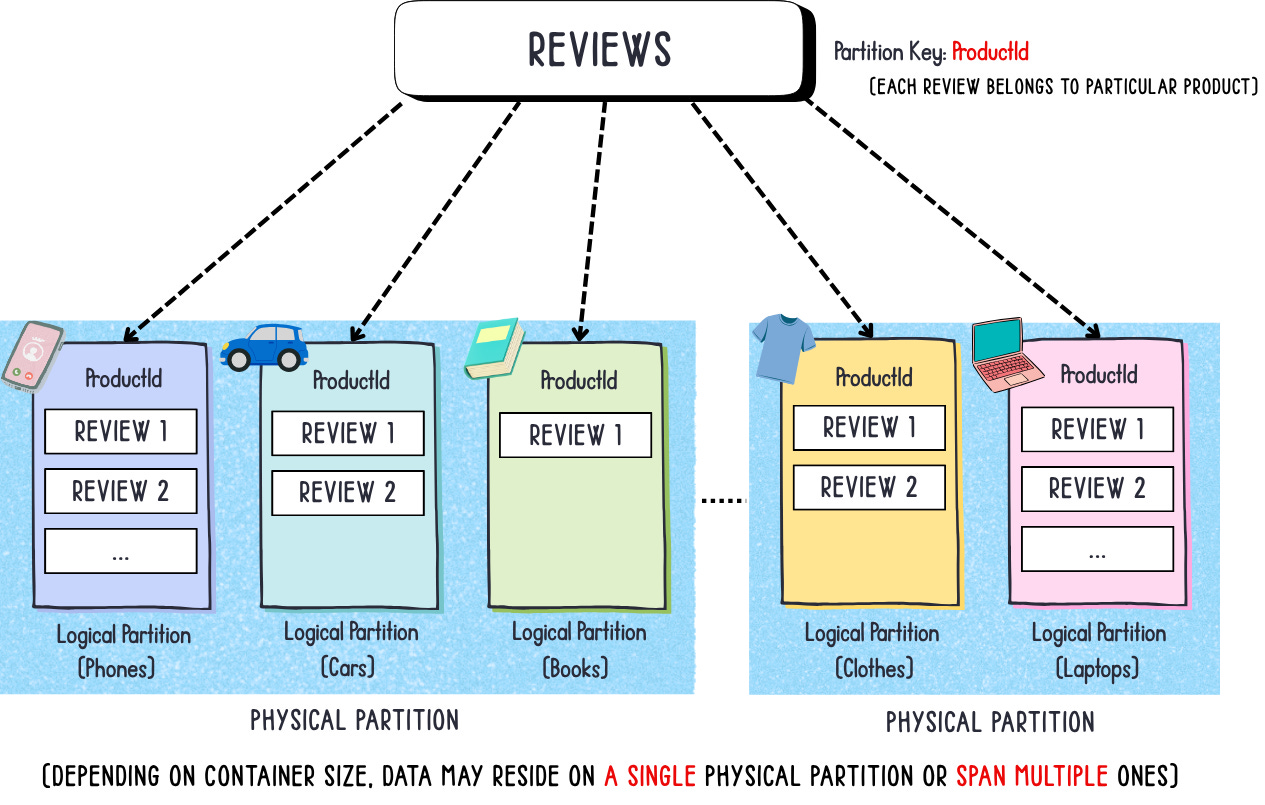
For example, whenever you’re fetching a product’s reviews, you’ll run a query like this:
SELECT *
FROM r
WHERE r.ProductId = "123"This query retrieves all reviews for the product with ID 123. Since all reviews for a given product reside in the same logical partition, Cosmos DB executes this as a single-partition query, ensuring low latency and efficient RU consumption.
Thanks
That’s a quick overview of the Cosmos DB partitioning fundamentals and the practical approach I personally use when designing data models. These are the core concepts that, once mastered, make it much easier to build scalable, high-performing solutions in Azure.
YouTube
Here’s a 10-minute video where I explain all this + a code demo.
If you want to really go deep into this topic, here’s links that I recommend: