
How to Build Software with AI That Actually Scales
Learn about PAIN Architecture methodology (based on the spec-driven approach)

The rise of agentic AI coding tools — Codex, Claude, and others — has fundamentally changed how software is built. Developers at every level, from junior engineers to senior architects, now rely on these tools to ship code faster than ever before. Meanwhile, business leaders, convinced by the promises of trillion-dollar AI companies, have begun pressuring their engineering teams to deliver AI-powered products at an unprecedented pace — often prioritizing speed over quality.
The result has been predictable: a wave of "vibe-coded" AI solutions riddled with bugs, negligible or negative ROI, and mounting technical debt. Many of these projects collapse under their own weight — the codebase becomes so tangled that even AI can no longer make sense of it.
After watching this pattern repeat itself so many times, I set out to find a better way. That work led me to develop a methodology I call Protected AI-Native Architecture (PAIN), which wraps around the principles of spec-driven development.
In this article, I'll walk you through how PAIN Architecture works — and why it matters for any team serious about building maintainable, production-grade software with AI.
A word of caution upfront: PAIN Architecture is more of an art than a science. The goal is for you to internalize the core principles, not follow a rigid checklist.
What is PAIN Architecture?
PAIN Architecture is a spec-first, AI-native development methodology. The core principle is simple: you do not write a single line of production code until your environment is structured in a way that AI agents can understand, follow, and be constrained by.
The methodology unfolds across two sequential phases:
AI-Native Architecture Phase
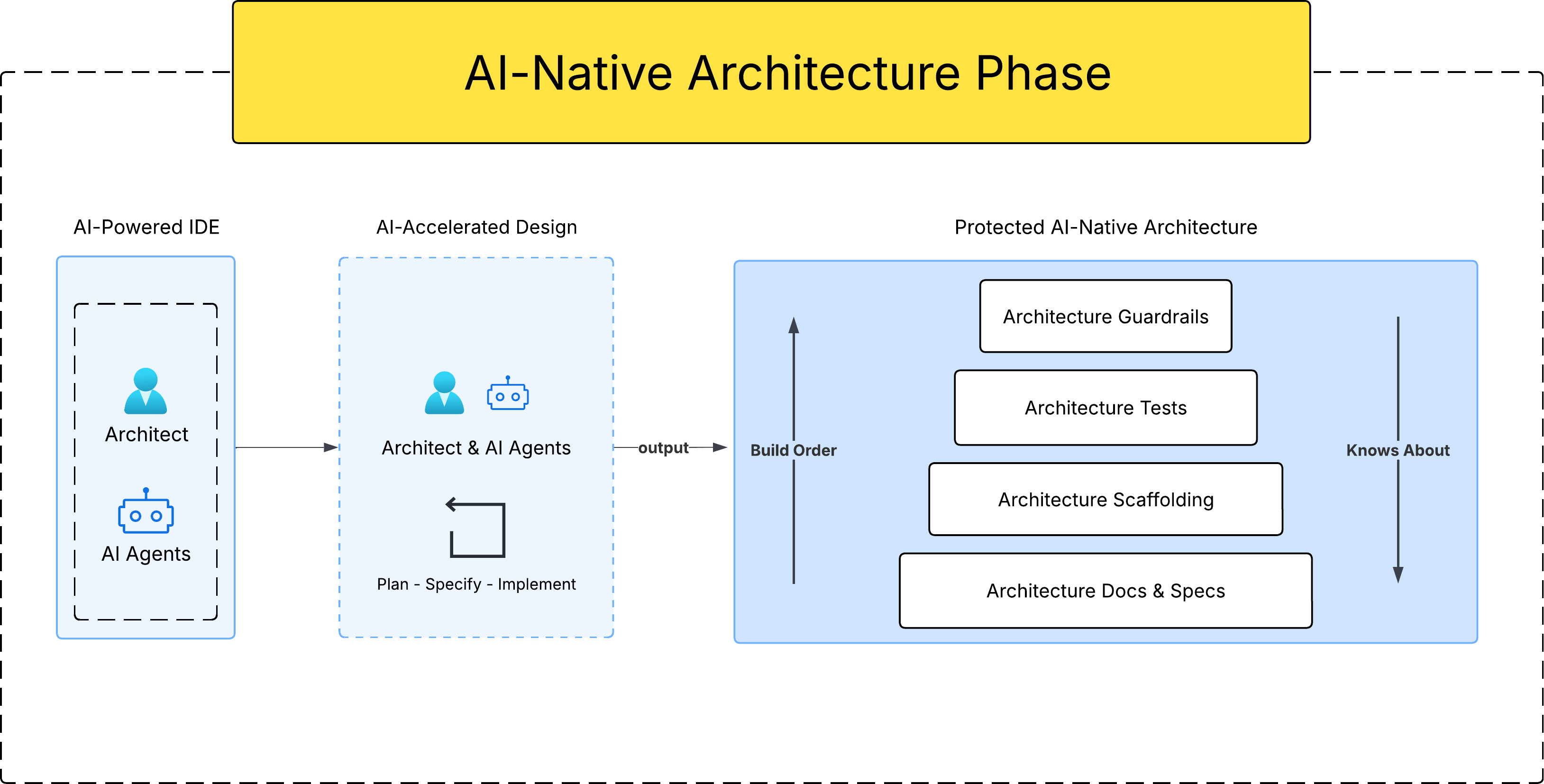
The Architecture Phase is where the entire foundation of your solution is established. It is driven by two key actors working in tandem:
The Architect (Human) — asks the right questions, shapes the solution, and translates business requirements into structured documentation (markdown specs and docs). AI can assist in clarifying and refining ideas, but the human remains the primary decision-maker here.
AI Agents — take the produced specs and use them to scaffold the codebase: the initial code structure that reflects the chosen architectural pattern (Clean Architecture, Vertical Slices, CQRS, Event-Driven, etc.).
The Architecture Loop
The architect and AI iterate together through a continuous Plan → Specify → Implement loop until the following core artifacts are produced:
Architecture Docs & Specs — Comprehensive markdown files that document all decisions, constraints, and design rationale. These serve as the single source of truth for both human developers and AI agents.
Architecture Scaffolding — The initial code structure generated from the specs, ensuring the project starts with a clean, intentional design rather than evolving organically (and chaotically) over time.
Architecture Tests & Guardrails — Automated tests that enforce architectural boundaries, combined with agent-level guardrails (subagents, hooks, instructions) that prevent both AI and humans from violating the established structure. This is what makes the architecture protected.
Once all three artifacts are in place, the project is ready to move into the AI-Native Development Phase — with a well-defined, protected architecture guiding every feature that follows.
AI-Native Development Phase
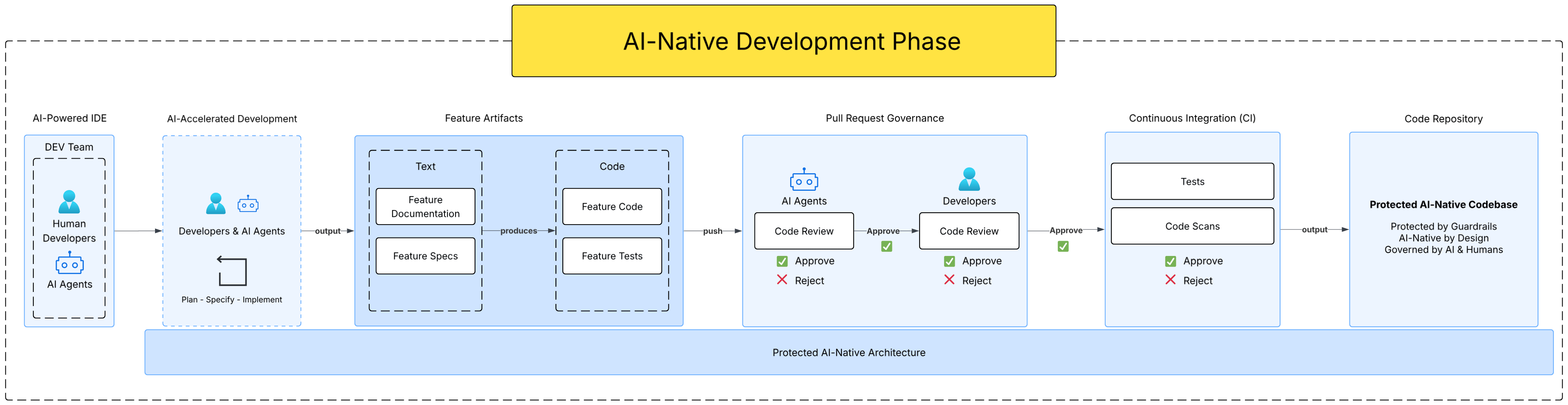
The key distinction between this approach and pure vibe coding is structure with enforceable boundaries. The Development Phase doesn't just encourage good practices — it enforces them through the guardrails and tests put in place during the Architecture Phase.
Every feature follows a strict spec-driven workflow:
Feature Spec First — Before any code is written, a dedicated spec file (e.g., feature-x.md) is created that thoroughly defines the feature: its requirements, expected behavior, edge cases, and implementation approach. This provides full observability over the development process — you always know why a decision was made, and you can always reimplement any feature from scratch by pointing the AI at its spec. All spec files remain in the codebase as living documentation.
Pull Request Governance — When a feature is complete and tests are written, it is submitted via a Pull Request. The PR undergoes a dual-review process:
First, AI agents perform a code review — checking for spec compliance, architectural violations, code quality issues, and test coverage. They can approve or reject.
Then, a human developer performs the final review — applying judgment, domain knowledge, and business context that AI may lack. Only after both reviews approve does the feature proceed.
Continuous Integration (CI) — Upon approval, the code enters the CI pipeline where automated tests and code scans run. This is the last line of defense before the code enters the Protected AI-Native Codebase.
The Protected AI-Native Codebase
The end result of this entire process is a codebase that is:
Protected by Guardrails — automated constraints prevent architectural drift, ensuring the codebase remains structured and maintainable as it grows.
AI-Native by Design — every part of the codebase is structured to be legible and navigable by AI agents, making ongoing AI-assisted development more effective and reliable.
Governed by AI & Humans — neither AI nor humans operate unchecked. Both are held accountable to the same architectural standards throughout the entire SDLC, from initial design to CI/CD and delivery.
Watch the Demo
If you'd like to see PAIN Architecture in action, I recorded a full walkthrough demonstrating how this methodology works end-to-end. Check it out here: https://youtu.be/oOFUk1asbsE